This month, I’ve shifted my research focus slightly, moving from my initial experiment to exploring the utility of large language models (LLMs) like GPT-4—for research in social and behavioral sciences.
The Challenge
In my initial proposal, I aimed to study the effects of online debates on participants’ perceptions and their subsequent belief adjustments. To accomplish this, I would have to manually generate posts and hundreds of comments mimicking an online debate. While crafting 10 comments might be manageable, scaling that up to 480 becomes overwhelming. That’s when I turned to ChatGPT for help. The next hurdle was to validate them. Traditionally, researchers rely on pilot studies to validate their experimental materials. But given the sheer volume of comments —about 480 —running a pilot would be expensive. So, could ChatGPT also help me to pilot-test my material? Interestingly, emerging research asks the same question: Can LLMs substitute for human participants in social and behavioral science studies?
The Promise of AI in Research
AI has long been criticized for lacking ‘social intelligence,’ despite its successes in various fields like defeating human Go players. The advent of models like ChatGPT changed this perception, as these models seem to grasp emotional and social nuances in conversations.
The Science Behind Large Language Models
For those unfamiliar, think of LLMs as highly advanced versions of the regressions in high school math. While regression use x and y to determine a best-fit line with 2 parameters (often denoted as y = a +bx), LLMs are based on deep neural networks (DNNs) with billions of parameters, trained on an extensive dataset of human-generated text. This enables them to recurrently predict the next word given a sequence of words to generate new text. More excitingly, as human language encompasses rich information about our mind, LLMs seem to be able to perform more complex tasks that are traditionally considered hard for AIs, from understanding emotions to making moral judgments.

Empirical Evidence
Recent empirical studies add credence to the notion that LLMs can tackle traditionally human-centric tasks. This includes not just straightforward tasks like detecting emotions or incivility but also more complex activities like moral reasoning. One study found GPT’s judgments on emotion, sentiment, and offensiveness to correlate with human evaluations at a rate ranging between 0.66 and 0.75. Even more astonishingly, another study revealed that GPT-3.5’s moral judgments exhibited a remarkable 0.96 correlation with human assessments.
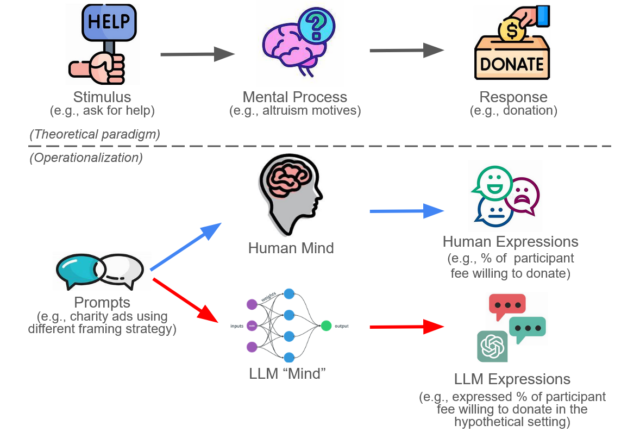
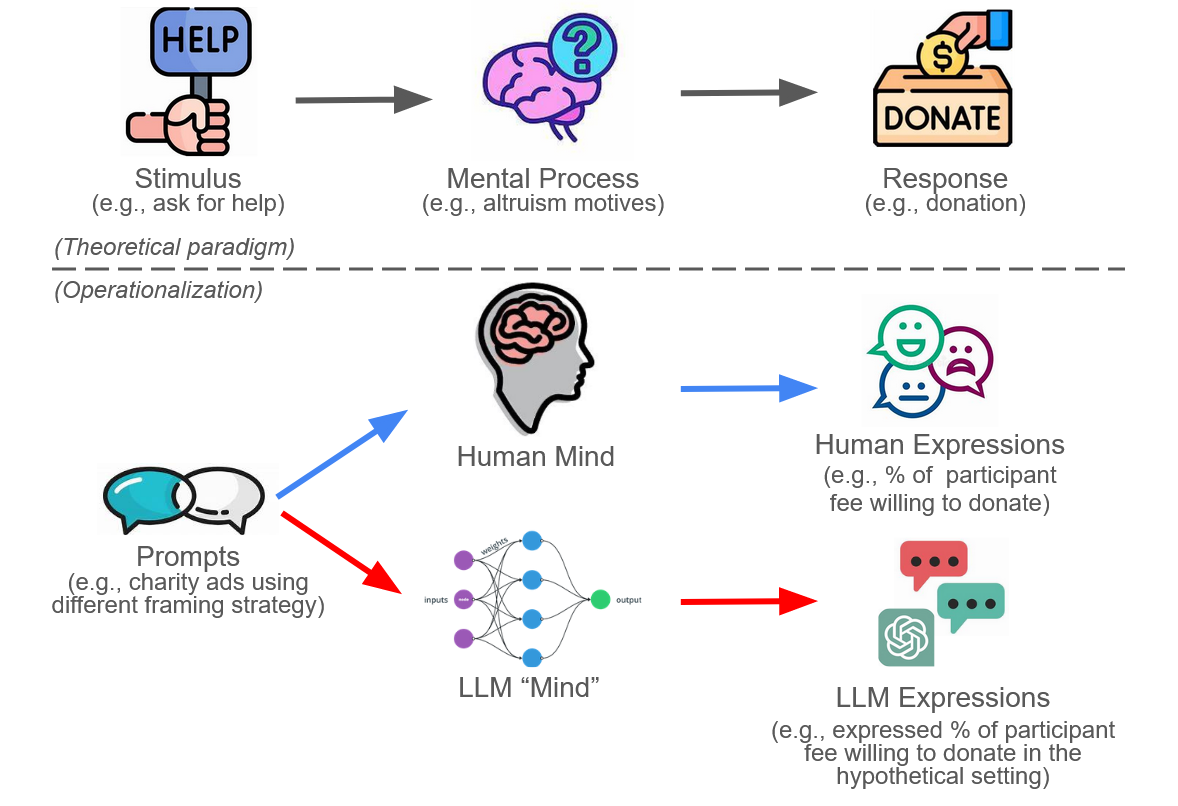
Thus, the expression generated by GPT seems a good proxy for human response (proxy 2). GPT4 not only demonstrates the ability to perform complex natural language processing tasks, but also considers the general variability of humans. However, it is worth noting that, although DNNs—the architecture underlying LLMs —were initially inspired by biological neural networks, the similarities largely end there. DNNs are much simpler and lack the degree of functional specialization and are designed for specific tasks. So while LLMs share a similar functionality (a true proxy 2), little evidence suggests that the underlying DNNs closely mimic the actual human brain (a false proxy 1). By developing this framework, it becomes feasible to consider substituting research traditionally conducted with human participants in social and behavioral sciences (blue routes in Figure 2) with research involving LLMs (red routes in Figure 2).
In the next blog, I will discuss some considerations and limitations for using these LLMs. Stay tuned 🙂