Introduction
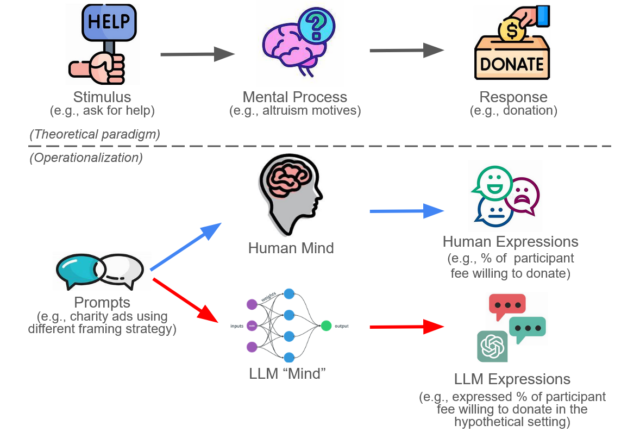
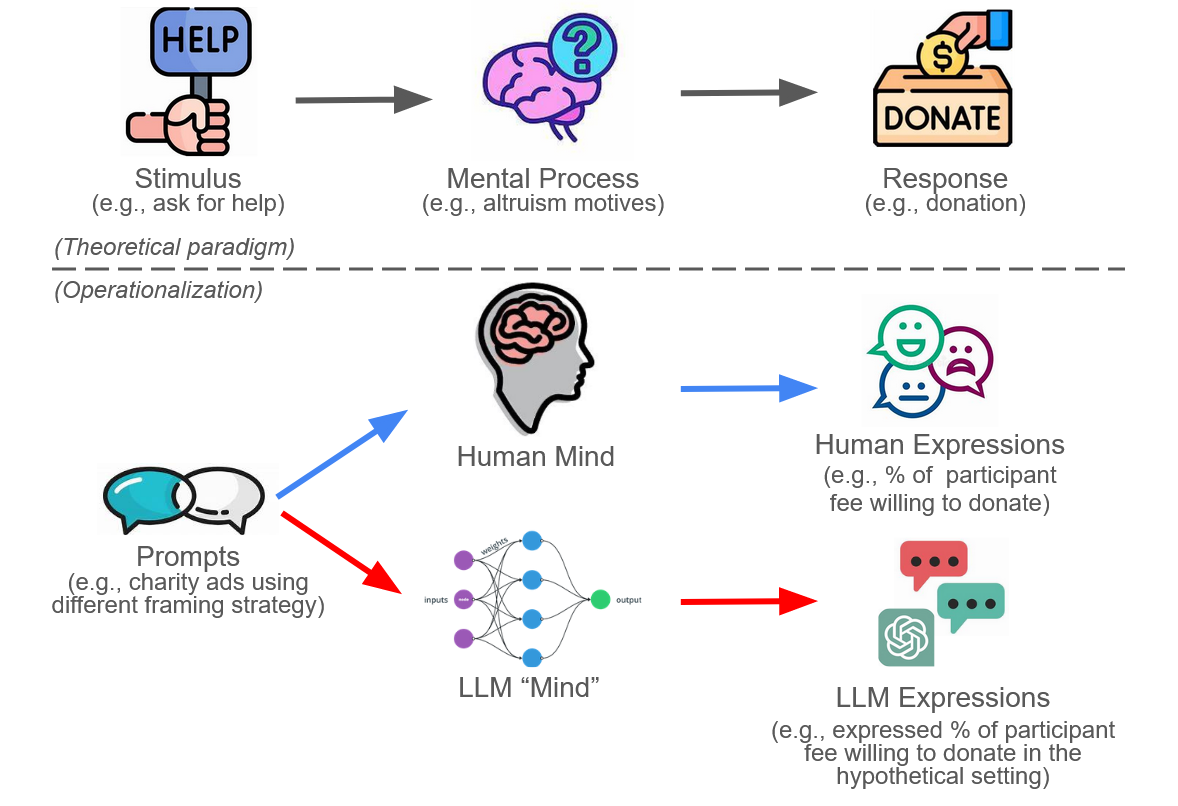
In the previous post, we created a framework (figure 1) showing how the use of Large Language Models (LLMs) like GPT-4 has potential to start a revolution across the realms of social and behavioral sciences. The idea of substituting LLMs for human participants in research is tantalizing but comes with its own set of challenges and limitations. This second blog post delves into these dimensions to provide a balanced view of using LLMs in research contexts.
Applicability of LLMs: When Do They Fit?
Firstly, as LLMs are trained primarily to generate text by predicting the next word given a sequence of words. It is no surprise that they are best suited for research where the stimulus and response are largely language-based. For instance, GPT-4 is well-equipped to assess incivility and offensiveness in social media comments. Similarly, given evidence that GPT-4 can emulate the opinions of specific subgroups, it might be appropriate to assign a particular identity to the model when individual differences are of interest. Some behavioral tasks can even be translated into language prompts for LLMs, as demonstrated by GPT-3’s performance in the multi-armed bandit task. However, it should be cautious as the reliability of LLMs decreases as tasks move away from language-based activities or require a nuanced understanding of complex human behaviors like non-verbal cues or crowd dynamics.
Demographic Representation: Who is the LLM Speaking For?
A second consideration is that as LLMs are trained on text, whom do these language models represent? Or, to put it more colloquially, who is the “GPT” people are conversing with? Studies have shown that LLMs like GPT-4 tend to align more closely with a young, liberal, and educated demographic. This could introduce biases and compromise the model’s performance on tasks requiring a broader demographic representation, as seen in its underperformance in sentiment analysis tasks for African languages.
Alignment with Human Cognition: What is Actually Learnt?
Lastly, as the DNNs underlying LLMs are nearly uninterpretable, determining the extent to which LLMs can mimic human cognition is complex. Thus, scientists have started to look at the similarity in expression of these LLMs and humans from an interesting perspective – how much do LLMs exhibit the same biases or fallacy as humans do? The answer, so far, is mixed. On one hand, LLMs appear to exhibit certain human-like biases. On the other hand, they perform more rationally in some other tasks where humans commonly err, but struggle in areas that are comparatively simple for humans. Moreover, their response varies considerably depending on the phrasing of a task or question. These results make it challenging to understand if they have acquired genuine reasoning abilities or are merely pattern-matching based on their extensive training data.
Conclusion: A Cautionary Optimism
The prospect of using LLMs as research proxies is promising but warrants careful scrutiny mentioned above. While they offer a cost-effective and efficient alternative for specific language-based tasks, their limitations in demographic representation and complex human behaviors cannot be overlooked. Furthermore, as they gain social influence, ethical considerations become increasingly critical.